Google DialogFlow – capturing numbers with voice
August 12, 2022
The following is my experience working with Google DialogFlow in a voice environment, and the seemingly simple task of capturing long strings of numbers correctly.
DialogFlow Overview
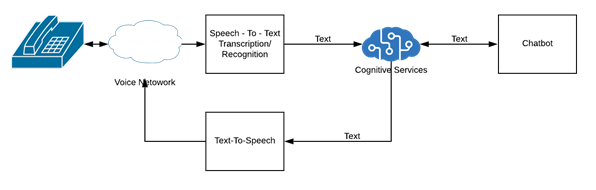
Google’s DialogFlow environment is a great place to build natural-language understanding applications that automate both text-based (“chatbot”) and voice-based interactions. All of the voice-enabled AI environments in wide use today (Google’s DialogFlow, IBM’s Watson Assistant, and Amazon’s Lex are the big 3) enable voice communications by going through a 3-step process, where spoken input is first transcribed to text by a speech-to-text engine (STT), then given to a bot for analysis, and then sent through a text-to-speech (TTS) engine to produce audio back to the user.
Voice is not text!
In theory, having a common AI assistant that supports both voice and text inputs allows for a plug-and-play extension of a bot – a chatbot that is handling text-based questions from users can be extended to voice inputs without having to redesign, and redevelop the chatbot. And for simple, proof-of-concept style interactions, this is true. But text and voice have significant differences, and adjusting the design of the interaction to match the mode of input can make a measurable impact on the success of the application.
And, the speech-to-text process often introduces unique challenges. One area where this is evident is for the task of collecting numeric input. For a recent project, we required a voice-enabled Google DialogFlow voice interaction to collect a 16-digit account number from a user. A regular expression entity does this for a text-enabled chatbot:
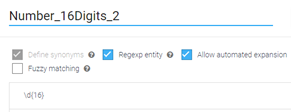
A simple regular expression works great for capturing the typical “1234567890123456” style input that chat users would enter. In practice, Google’s STT engine provides input in other formats, including:
- “1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6” – spaces in between digits
- “one two three four five six seven eight nine zero one two three four five six” – words
- “1 2 three four 5 six 7 8 9 zero one two 3 4 five 6” – my favorite, a mix of digits and words!
- “1234567890123456” – same as the text-based input
This is documented by Google, special_handling_for_speech_recognition, but the documentation fails to describe the mixed-mode input format as possible. Also, a regular expression entity does not enable Auto speech adaptation – a very important capability where the STT engine can work better if it knows what it’s looking for from the intents and entities that are active.
The following steps can be used to solve this problem and all similar numeric data input requirements on Google’s DialogFlow platform:
-
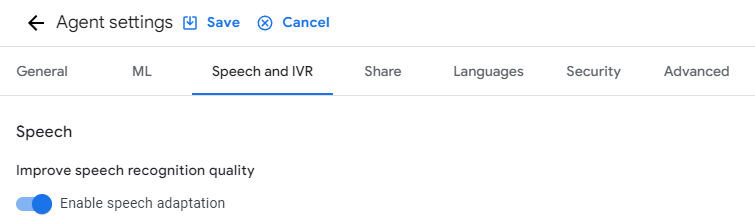
Ensure Speech Adaptation is enabled. In the “Speech and IVR” settings for the agent, speech adaptation needs to be turned on:
-
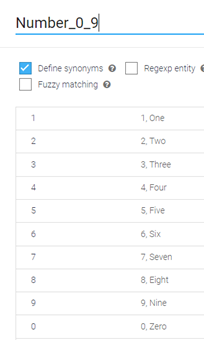
Create an Entity for capturing single digits (0-9), along with the corresponding words (zero-nine) as synonyms. In this example that Entity is named “Number_0_9”:
-
Create an entity for your specific use case for the number of digits that need to be captured. In this example, we have a 4-digit number use case. There is a space in-between each value in the screenshot below. A word of caution, this compound entity preserves the initial input text. An input of “one two 3 4” will provide you a match of “one two 3 4” (not the 1 2 3 4 that you would expect) – you will need to handle this either in your application or in fulfillment. Compound entities like this do not translate input synonyms to a common format like a plain entity would (this may be fixed in future updates by Google).
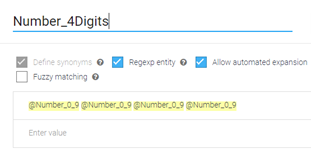
-
Create a regular expression entity for the case of a contiguous string of digits:
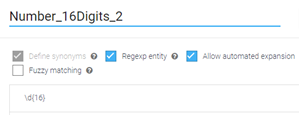
-
Either create two intents (one for each entity type, which is what we did), or a single intent with both entity types available and use fulfillment to provide the matched value back to the user. Your application’s flow will dictate how you craft the intent(s) that utilize the entities correctly.
-
Lastly, we can give the STT engine an additional performance boost by letting it know that we are collecting digits. A class token of $OOV_CLASS_DIGIT_SEQUENCE will let the STT engine’s speech adaptation module know it should process input as a string of digits and produces dramatically improved results. Google documents how to set this class token here: class_tokens.
By following this process, our phone-based solution is capturing the caller’s 16-digit account number very reliably – at least as well as the traditional non-AI IVR application that it replaced.